# 目录
# 1. 说明
该功能实际是一个增强功能,在原有功能的基础上添加了动态配置。
主要为了解决由于第三方平台页面结构的调整导致【文章搬运工】功能无法使用的问题。
现在的文章搬运工功能,在加载配置文件的时候,优先从数据库中获取配置文件,当未添加该配置时,会使用 blog-admin/src/main/resources/HunterConfig.json 作为兜底
# 2. 自定义配置
编辑如下内容:
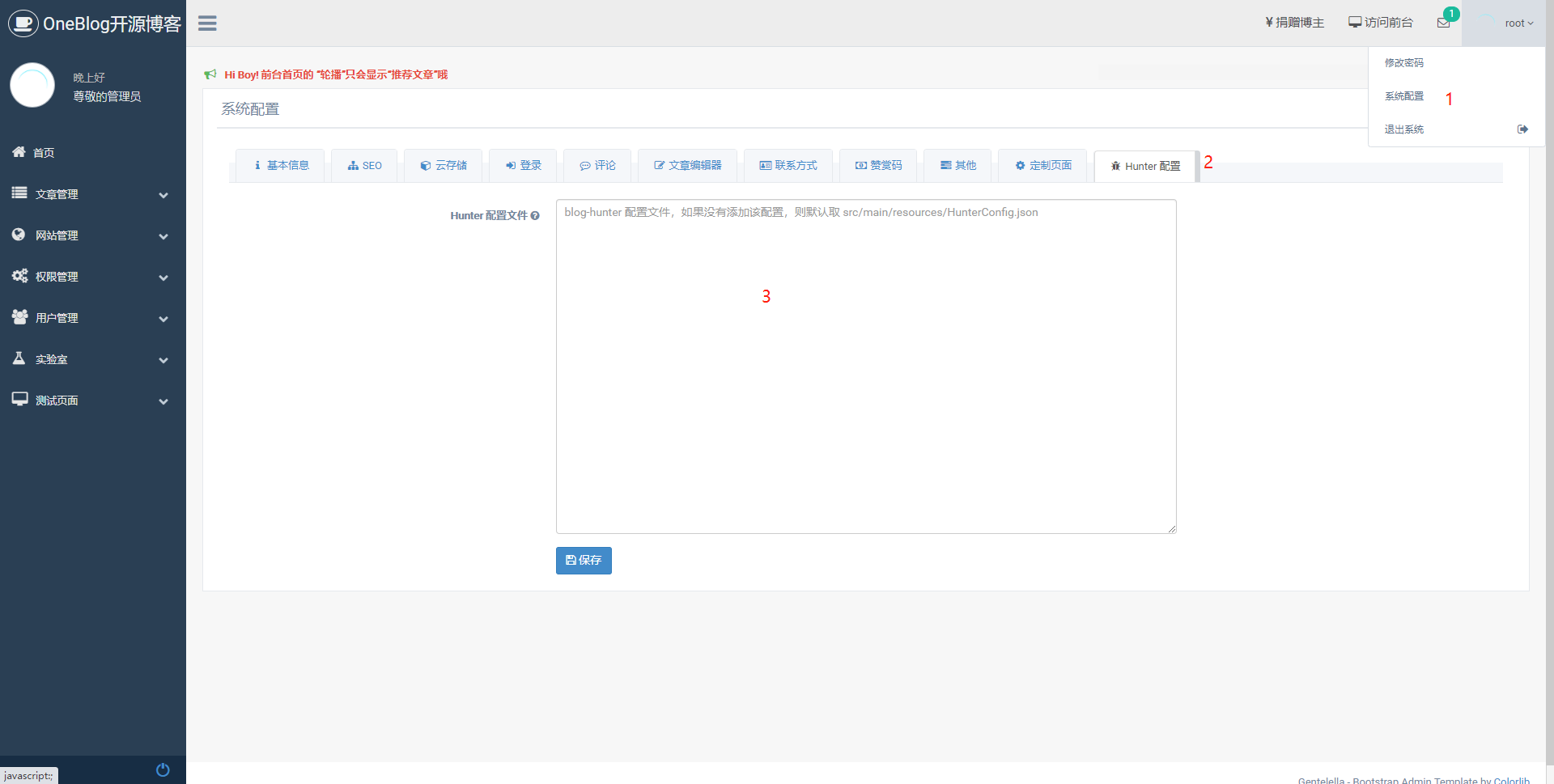
自定义配置时,请严格遵照 blog-hunter - 配置信息 (opens new window) 的配置说明修改,也可以直接复制 blog-admin/src/main/resources/HunterConfig.json 中的内容进行修改
完整 json 内容如下:
{
"imooc": {
"domain": "www.imooc.com",
"titleRegex": "//span[@class=js-title]/html()",
"authorRegex": "//div[@class=name_con]/p[@class=name]/a[@class=nick]/html()",
"releaseDateRegex": "//div[@class='dc-profile']/div[@class='l']/span[@class='spacer']/text()",
"contentRegex": "//div[@class=detail-content]/html()",
"tagRegex": "//div[@class=cat-box]/div[@class=cat-wrap]/a[@class=cat]/html()",
"descriptionRegex": "//meta[@name=Description]/@content",
"targetLinksRegex": "/article/[0-9]{1,10}",
"header": [
"Host=www.imooc.com",
"Referer=https://www.imooc.com"
],
"entryUrls": [
"https://www.imooc.com/u/{uid}/articles?page=1"
]
},
"csdn": {
"domain": "blog.csdn.net",
"titleRegex": "//h1[@class=title-article]/html()",
"authorRegex": "//a[@class=follow-nickName]/html()",
"releaseDateRegex": "//div[@class=article-bar-top]/div[@class='bar-content']/span[@class=time]/html()",
"contentRegex": "//div[@id=content_views]/html()",
"tagRegex": "//span[@class=artic-tag-box]/a[@class=tag-link]/html()",
"targetLinksRegex": "(((http|ftp|https):\\/\\/[0-9a-zA-Z]{1,15}.blog.csdn.net/article/details/[0-9a-zA-Z]{1,15})|((http|ftp|https):\\/\\/blog.csdn.net/{uid}/article/details/[0-9a-zA-Z]{1,15}))",
"header": [
"Host=blog.csdn.net",
"Referer=https://blog.csdn.net/{uid}/article/list/1"
],
"entryUrls": [
"https://blog.csdn.net/{uid}/article/list/1"
]
},
"iteye": {
"domain": "{uid}.iteye.com",
"titleRegex": "//div[@class=blog_title]/h3/text()",
"authorRegex": "//div[@id=blog_owner_name]/html()",
"releaseDateRegex": "//div[@class=blog_bottom]/ul/li[1]/html()",
"contentRegex": "//div[@class=iteye-blog-content-contain]/html()",
"tagRegex": "//div[@class=news_tag]/a/html()",
"targetLinksRegex": ".*{uid}\\.iteye\\.com/blog/[0-9]+",
"header": [
"Host={uid}.iteye.com",
"Referer=http://{uid}.iteye.com/"
],
"entryUrls": [
"http://{uid}.iteye.com/?page=1"
]
},
"cnblogs": {
"domain": "www.cnblogs.com",
"titleRegex": "//a[@id=cb_post_title_url]/html()",
"authorRegex": "//div[@class=postDesc]/a[1]/html()",
"releaseDateRegex": "//span[@id=post-date]/html()",
"contentRegex": "//div[@id=cnblogs_post_body]/html()",
"tagRegex": "//div[@id=EntryTag]/a/html()",
"descriptionRegex": "//meta[@property=\"og:description\"]/@content",
"targetLinksRegex": ".*www\\.cnblogs\\.com/{uid}/p/[\\w\\d]+\\.html",
"header": [
"Host=www.cnblogs.com",
"Referer=https://www.cnblogs.com/"
],
"entryUrls": [
"https://www.cnblogs.com/{uid}/default.html?page=1"
]
},
"juejin": {
"domain": "juejin.im",
"titleRegex": "//h1[@class=article-title]/html()",
"authorRegex": "//div[@itemprop=author]/meta[@itemprop=\"name\"]/@content",
"releaseDateRegex": "//meta[@itemprop=\"datePublished\"]/@content",
"contentRegex": "//div[@class=article-content]/html()",
"tagRegex": "//div[@class=tag-title]/html()",
"targetLinksRegex": ".*juejin\\.im/post/[\\w\\d]+",
"header": [
"Host=juejin.im",
"Referer=https://juejin.im"
],
"entryUrls": [
"https://juejin.im/user/{uid}/posts"
]
},
"v2ex": {
"domain": "v2ex.com",
"titleRegex": "//*[@id=Main]/div[@class=box]/div[@class=header]/h1/html()",
"authorRegex": "//*[@id=Main]/div[@class=box]/div[@class=header]/small/a/html()",
"releaseDateRegex": "//meta[@property=\"article:published_time\"]/@content",
"contentRegex": "//div[@class=markdown_body]/html()",
"tagRegex": "//*[@id=\"Main\"]/div[6]/div/a/html()",
"descriptionRegex": "//meta[@property=\"og:description\"]/@content",
"targetLinksRegex": ".*www\\.v2ex\\.com/t/[\\w\\d]+",
"header": [
"Host=www.v2ex.com",
"Referer=https://www.v2ex.com"
],
"entryUrls": [
"https://www.v2ex.com/member/{uid}"
]
},
"oschina": {
"domain": "oschina.net",
"titleRegex": "//h1[@class=article-box__title]/a/text()",
"authorRegex": "//div[@class=article-box__meta]/div[@class=item-list]/div[2]/a/html()",
"releaseDateRegex": "//div[@class=article-box__meta]/div[@class=item-list]/div[4]/html()",
"contentRegex": "//div[@class=content]/html()",
"tagRegex": "//div[@class=tags-box]/div[@class=tags-box__inner]/a/html()",
"targetLinksRegex": "https://my.oschina.net/.*/blog/[0-9]{1,10}",
"header": [
"Host=my.oschina.net",
"Referer=https://my.oschina.net"
],
"entryUrls": [
"https://my.oschina.net/{uid}",
"https://my.oschina.net/u/{uid}"
]
},
"jianshu": {
"resolver": {
"releaseDate": {
"type": "regex",
"clazz": "java.lang.Long",
"operator": "* 1000"
}
},
"domain": "jianshu.com",
"titleRegex": "//h1[@class=_1RuRku]/text()",
"authorRegex": "//span[@class=_22gUMi]/html()",
"releaseDateRegex": ".*\"first_shared_at\":([0-9]+),.*",
"contentRegex": "//article[@class=_2rhmJa]/html()",
"tagRegex": "//div",
"targetLinksRegex": "/p/[0-9a-zA-Z]{1,15}",
"header": [
"Host=www.jianshu.com",
"Referer=https://www.jianshu.com/p/{uid}"
],
"entryUrls": [
"https://www.jianshu.com/p/{uid}",
"https://www.jianshu.com/u/{uid}"
]
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
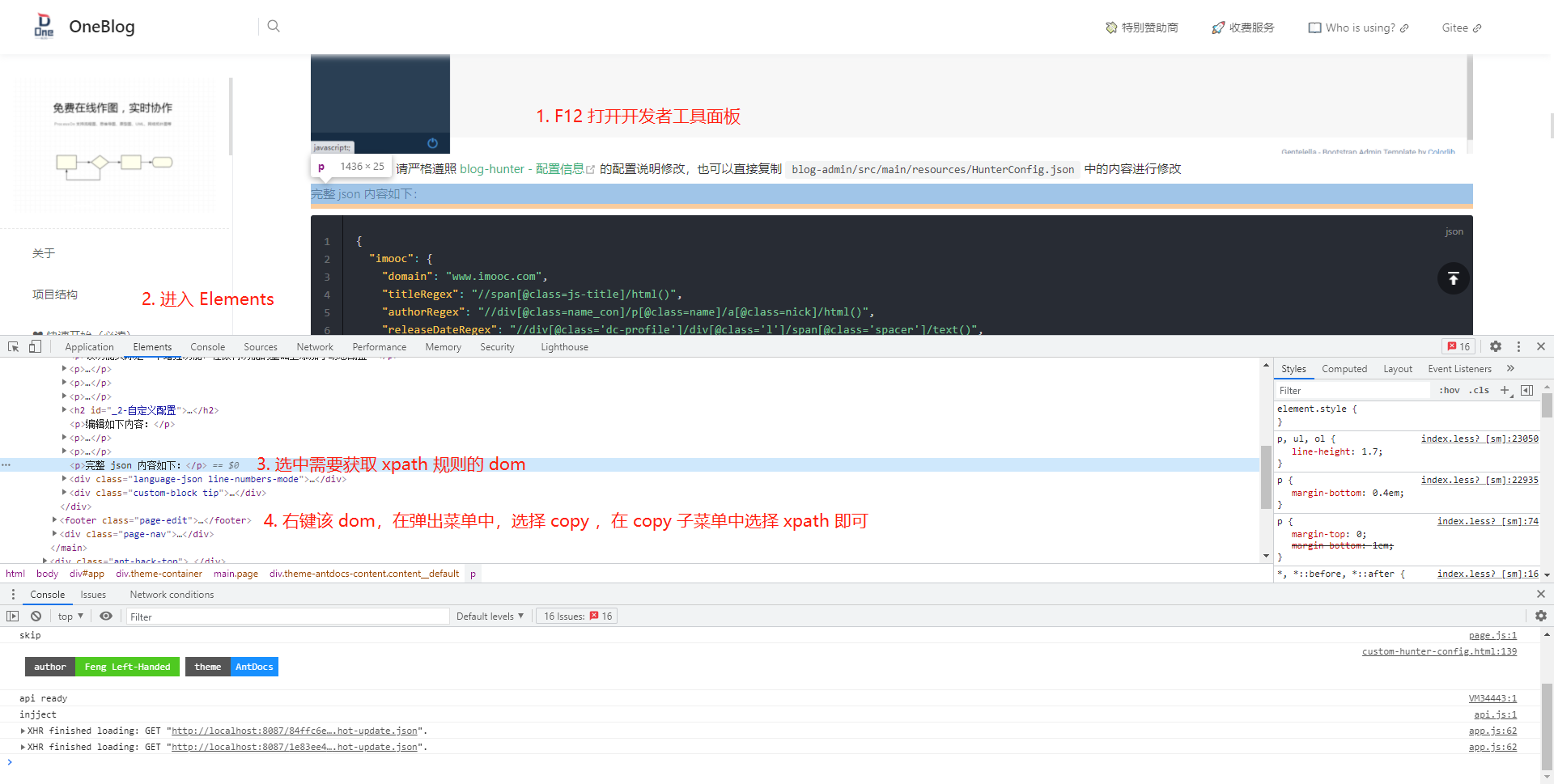
小技巧
HunterConfig.json 中以 Regex 结尾的配置,是使用的 xpath 表达式,获取 xpath 表达式的方式如下: